القليل من التاريخ
لقد قمت بالتعمق في برنامج جدولة Linux kernel مؤخرًا.
لإعطاء مقدمة مختصرة عن الجدولة، تخيل نظامًا واحدًا لوحدة المعالجة المركزية (CPU) وحيدة النواة. يخصص نظام التشغيل شرائح زمنية تبلغ بضعة ملي ثانية لتشغيل التطبيقات. إذا كان كل تطبيق يمكنه الحصول على بضعة ميلي ثانية بين الحين والآخر، فسيشعر النظام بأنه تفاعلي، وسيشعر المستخدم أن الكمبيوتر يقوم بتشغيل مئات المهام بينما يقوم الكمبيوتر بتشغيل مهمة واحدة فقط في أي وقت.
ثم أصبحت الأنظمة متعددة النواة ميسورة التكلفة للمستهلكين في أوائل العقد الأول من القرن الحادي والعشرين، وحصلت معظم أجهزة الكمبيوتر على 2 أو 4 مراكز ويمكن لنظام التشغيل تشغيل مهام متعددة بالتوازي بشكل حقيقي. أدى ذلك إلى تغيير الأمور قليلاً ولكن ليس كثيرًا، يمكن أن يحتوي الخادم بالفعل على 2 أو 4 وحدات معالجة مركزية فعلية في الخادم.
زاد عدد النوى بمرور الوقت ووصلنا إلى حالة في أوائل عام 2020 حيث كان خط الأساس هو خوادم AMD التي تحتوي على 128 نواة لكل وحدة معالجة مركزية.
بالنسبة للحكاية، تاريخيًا كانت الفترة على نظام التشغيل Windows حوالي 16 مللي ثانية، وكان لها أثر جانبي مضحك حيث سيتم استئناف التطبيق الذي يقوم بالنوم (1 مللي ثانية) بعد حوالي 16 مللي ثانية.
جدولة لينكس
العودة إلى Linux، نسخة قصيرة ومبسطة.
في Linux، يعمل برنامج جدولة kernel في فترات تبلغ 5 مللي ثانية (أو 20 مللي ثانية في الأنظمة متعددة النواة) لضمان أن كل تطبيق لديه فرصة للتشغيل خلال الـ 5 مللي ثانية التالية. من المفترض أن يتم استباق مؤشر الترابط الذي يستغرق أكثر من 5 مللي ثانية.
من المهم لوقت استجابة المستخدم النهائي. بعبارات عامة، عندما تقوم بتحريك الماوس ويتحرك الماوس على الشاشة على الأقل كل بضعة أجزاء من الثانية، يشعر الكمبيوتر بالاستجابة وهو أمر رائع. ولهذا السبب تم ترميز نواة Linux إلى 5 مللي ثانية إلى الأبد، لتوفير تجربة جيدة لمستخدمي سطح المكتب التفاعليين.
من البديهي أن يتغير سلوك المجدول عندما تحصل وحدة المعالجة المركزية على مراكز متعددة. ليست هناك حاجة لمقاطعة المهام بقوة طوال الوقت لتشغيل شيء آخر، عندما يكون هناك العديد من وحدات المعالجة المركزية (CPU) للعمل معها.
إنه عمل متوازن. لا ترغب في إعادة جدولة المهام كل بضعة ميلي ثانية إلى نواة أخرى، لأن ذلك يوقف المهمة ويتسبب في تبديل السياق وكسر ذاكرة التخزين المؤقت، مما يجعل جميع المهام أبطأ، ولكن عليك أن تحافظ على استجابة الأشياء، خاصة إذا كان سطح مكتب مع مستخدم نهائي هل هو سطح مكتب بالرغم من ذلك؟
يمكن ضبط المجدول باستخدام إعدادات sysctl. هناك العديد من الإعدادات المتاحة، راجع هذه المقالة للحصول على مقدمة ولكن اعلم أن جميع أرقام القياس خاطئة نظرًا لأنه تم ترميز النواة عن طريق الخطأ إلى 8 مراكز https://dev.to/satorutakeuchi/the-linux-s-sysctl-parameters-about -جدولة العمليات-1dh5
- sched_latency_ns
- sched_min_granularity_ns (أعيدت تسميتها إلى base_slice في الإصدار 6 من kernel)
- Wakeup_granularity_ns
يرتكب
أضاف هذا الالتزام تحجيمًا آليًا لإعدادات الجدولة مع عدد النوى في عام 2009.
لقد تم ترميزه عن طريق الخطأ إلى 8 مراكز كحد أقصى. أُووبس. القيمة السحرية تأتي من التزام قديم وبقيت كما كانت. يرجى الرجوع إلى الفرق الكامل على جيثب.

الإعداد المثير للاهتمام هو الحد الأدنى من التفاصيل، من المفترض أن يسمح بتشغيل المهام لمدة لا تقل عن 0.75 مللي ثانية (أو 3 مللي ثانية في الأنظمة متعددة النواة) عندما يكون النظام مثقلًا (هناك مهام أكثر للتشغيل في هذه الفترة أكثر من وحدة المعالجة المركزية) متاح).
تمت إعادة تسمية إعداد min_granularity إلى base_slice في هذا الالتزام في الإصدار السادس من kernel.
يقول التعليق أنه يتم قياسه باستخدام عدد وحدة المعالجة المركزية وأن التعليق غير صحيح. أتساءل ما إذا كان مطورو kernel على علم بهذا الخطأ أثناء قيامهم بإعادة كتابة المجدول!
- تشير التعليقات الرسمية في الكود إلى أنه يتم التوسع باستخدام log2(1+cores) ولكنه لا يحدث.
- جميع التعليقات في الكود غير صحيحة.
- الوثائق الرسمية وصفحات الدليل غير صحيحة.
- كل مقالة بالمدونة وإجابة تجاوز سعة المكدس ودليل منشور حول المجدول غير صحيحة.

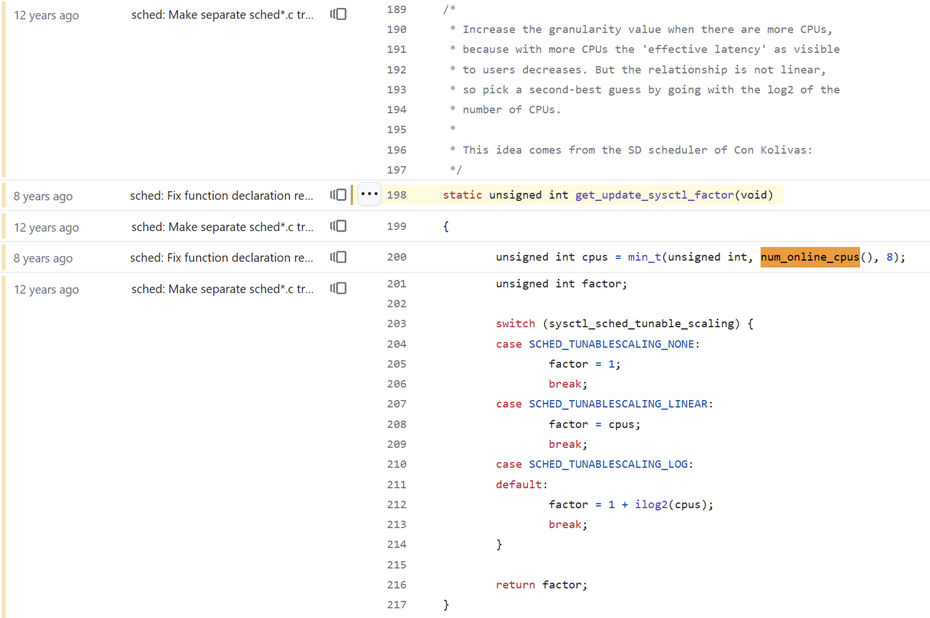
فيما يلي الوظيفة التي تقوم بالتحجيم. هذا هو الرمز الذي تم ترميزه فيه بحد أقصى 8 مراكز.
الحد الأقصى لعامل القياس هو 4 في الأنظمة متعددة النواة: 1+log2(min(cores, 8)).
الإعداد الافتراضي هو استخدام مقياس السجل، ويمكنك ضبط إعدادات kernel لاستخدام القياس الخطي بدلاً من ذلك ولكنه معطل أيضًا، ومحدد بـ 8 مراكز.
يحتوي سطح مكتب AMD الحديث على 32 مؤشر ترابط، بينما تحتوي خوادم AMD الحديثة على 128 مؤشر ترابط لكل وحدة معالجة مركزية وغالبًا ما تحتوي على وحدات معالجة مركزية فعلية متعددة.
من الصعب أن تكون النواة مشفرة بحد أقصى 8 مراكز (عامل القياس 4). ليس من الجيد إعادة جدولة مئات المهام كل بضعة أجزاء من الثانية، ربما على نواة مختلفة، أو ربما على قالب مختلف. لا يمكن أن يكون جيدًا للأداء وذاكرة التخزين المؤقت.
في الختام، تم تشفير النواة عن طريق الخطأ إلى 8 مراكز على مدار الخمسة عشر عامًا الماضية ولم يلاحظ أحد.
أُووبس. ¯\_(ツ)_/¯

&&&&&
- sched_latency_ns
- sched_min_granularity_ns (أعيدت تسميتها إلى base_slice في الإصدار 6 من kernel)
- Wakeup_granularity_ns
يرتكب
https://github.com/torvalds/linux/commit/acb4a848da821a095ae9e4d8b22ae2d9633ba5cd
ة
- تشير التعليقات الرسمية في الكود إلى أنه يتم التوسع باستخدام log2(1+cores) ولكنه لا يحدث.
- جميع التعليقات في الكود غير صحيحة.
- الوثائق الرسمية وصفحات الدليل غير صحيحة.
https://github.com/torvalds/linux/commit/e4ec3318a17f5dcf11bc23b2d2c1da4c1c5bb507